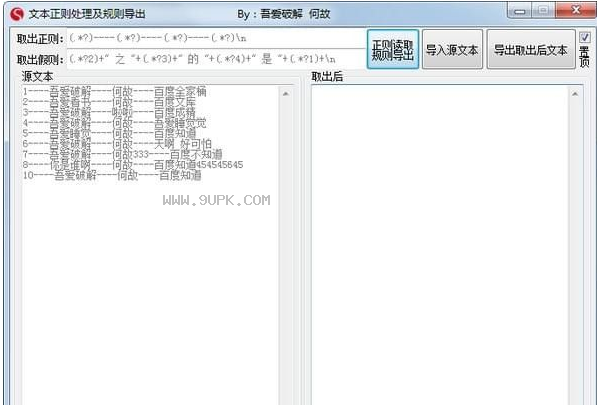
文本文档批量处理导入导出大师是一款非常好用的文字处理工具。通过正则表达式来轻松处理文本文档文本文档批量处理导入导出大师。这款工具取出文本是正则获取,而规则导出就是用的作则的假正则,取出可以自定义。有需...
基本信息
评分 8
文本文档批量处理导入导出大师是一款非常好用的文字处理工具。通过正则表达式来轻松处理文本文档文本文档批量处理导入导出大师。这款工具取出文本是正则获取,而规则导出就是用的作则的假正则,取出可以自定义。有需要的用户欢迎来gz85下载站下载~
文本正则处理及规则导出工具又称文本文档批量处理导入导出大师,取出文本用的是正则获取,规则导出用的是作者自己开发的假规则,简称假则,取出可以自定义!
1.下载完成后不要在压缩包内运行软件直接使用,先解压;
2.软件同时支持32位64位运行环境;
3.如果软件无法正常打开,请右键使用管理员模式运行。
字符是计算机软件处理文字时最基本的单位,可能是字母,数字,标点符号,空格,换行符,汉字等等。字符串是0个或更多个字符的序列。文本也就是文字,字符串。说某个字符串匹配某个正则表达式,通常是指这个字符串里有一部分(或几部分分别)能满足表达式给出的条件。
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
正则表达式的三种文本处理工具、命令。
I.grep
1.gerp的常用参数
-n只显示行号
-o只显示匹配的内容
-q静默模式,没有输出,需要使用$?来判断有没有过滤到自己想要的东西
-l如果匹配成功,则输出文件名称,如果失败则不输出,通常会-rl一起连用
-A如果匹配成功,会将匹配到的内容和后N行一起输出
-B如果匹配成功,会将匹配到的内容和前N行一起输出
-C如果匹配成功,会将匹配到的内容和前后N行一起输出
-c如果匹配成功,会将匹配内容的行数输出
-Egrep的扩张,相当于egrep
-i忽略大小写
-v取反,不匹配
-w匹配单词
2.正则介绍
^行首
$行尾
.除了换行符以外的单个字符
*前导字符的零个或多个
.*所有字符
[]字符组内的任一字符
[^]对字符组内的每个字符取反(不匹配字符组内的每个字符)
^[^]非字符组内的字符开头行
[a-z]小写字母
[A-Z]大写字母
[a-z]小写和大写字母
[0-9]数字
扩展正则sed加-r参数或转义
grep加-E或egrep或转义
AWK直接支持但不包含{n,m}
?前导字符零个或一个
+前导字符一个或多个
x{m}x出现m次
x{m,}x出现m至多次
x{m,n}x出现m至n次
II.sed
流编辑器streamediter,是以行为单位的处理程序。
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以行为单位进行处理,可以将数据行进行替换、删除、新增、选取等特定工作。
1.命令格式
sed[-nefri]‘command’输入文本
2.常用选项
-n∶使用安静(silent)模式。在一般sed的用法中,所有来自STDIN的资料一般都会被列出到萤幕上。但如果加上-n参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来。
-e∶直接在指令列模式上进行sed的动作编辑;
-f∶直接将sed的动作写在一个档案内,-ffilename则可以执行filename内的sed动作;
-r∶sed的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法)
-i∶直接修改读取的档案内容,而不是由萤幕输出。
3.常用命令
a新增,a的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c取代,c的后面可以接字串,这些字串可以取代n1,n2之间的行!
d删除,因为是删除啊,所以d后面通常不接任何咚咚;
i插入,i的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p列印,亦即将某个选择的资料印出。通常p会与参数sed-n一起运作~
s取代,可以直接进行取代的工作哩!通常这个s的动作可以搭配正规表示法!例如1,20s/old/new/g就是啦
III.awk
awk是行处理器,依次对每一行进行处理,然后输出
1.命令格式
awk[options]'commands'files
2.常用选项
-F定义字段的分割符,默认的分隔符是连续的空格或制符表
-v定义变量并赋值也可以借用次方式从shell变量中引入
2.特殊要点
$0表示整个当前行
$1每行第一个字段
NF字段数量变量
NR每行的记录号,多文件记录递增
FNR与NR类似,不过多文件记录不递增,每个文件都从1开始
制表符
换行符
FSBEGIN时定义分隔符
RS输入的记录分隔符,默认为换行符(即文本是按一行一行输入)
~匹配,与==相比不是精确比较
!~不匹配,不精确比较
==等于,必须全部相等,精确比较
!=不等于,精确比较
&&逻辑与
+匹配时表示1个或者1个以上
/[0-9][0-9]+/两个或两个以上数字
/[0-9][0-9]*/一个或一个以上数字
FILENAME文件名
OFS输出字段分隔符,默认也是空格,可以改为制表符等
ORS输出的记录分隔符,默认为换行符,既处理结果也是一行一行输出
-F'[:#/]'定义三个分隔符
print是awk打印指定内容的主要命令